GPT-5 vs GPT-4.1 for Real-World IoT Data Analysis
Raj Nakarja, CEO and Chief Engineer | 19 August 2025
Modern LLMs are not databases or number‑crunchers—and if you naively dump raw timeseries into them, they’ll hallucinate, drop edge cases, and miss units. To make LLMs useful for data analysis, you must wrap them in a proper system: one that retrieves the right data, computes deterministically, and asks the model only to reason, plan, and explain.
In our experience, LLMs excel at three things:
Text compression: distilling long specs, schemas, and prior chats into concise working context. We use this to build compact analysis plans and keep prompts focused on what matters.
Fuzzy search within text: semantically locating relevant devices, fields, and time ranges across messy metadata, logs, and schemas. We use this to select the exact slice of data that should be analyzed.
Cross‑domain comparison: linking concepts, units, and heuristics across domains (e.g., “solar yield per m²” vs “kWh counters” vs “irradiance”). We use this to frame results, choose reasonable defaults, and translate findings for the end user.
Superstack’s Agent is designed around those strengths. It never lets the model “touch” your raw rows directly. Instead, it orchestrates three steps:
Filter: identify precisely which data is relevant,
Analyze: run deterministic code on that data in a secure runtime,
Explain: turn results into clear, contextual answers—along with the model’s reasoning.
In this article, we’ll show how the Superstack Agent works end‑to‑end and share what changes with GPT‑5: better instruction‑following and robustness, but with notable latency trade‑offs. You’ll see where GPT‑5 helps, where it can slow things down, and how we’re optimizing prompts and execution to get the best of both.
How does the agent work?
The Superstack agent works through a series of orchestrated steps that transform natural language queries into precise data analysis. Each step leverages the LLM’s strengths while maintaining strict separation between the AI models and your raw IoT data.
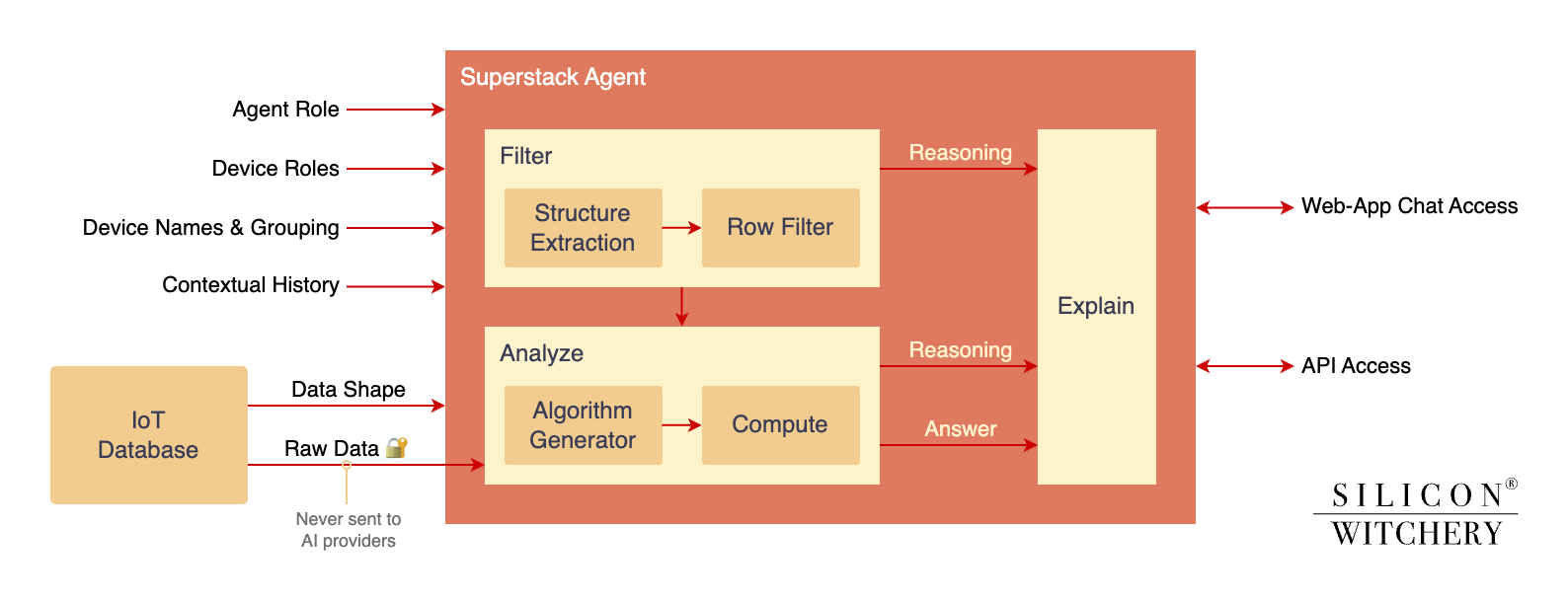
Let’s examine these steps in detail with a simple example query for a deployment of plant health monitors - consider the user asks What's the average temperature in my greenhouse?
1. Filter
The Filter step analyzes your deployment’s metadata and data structure to determine what information is relevant to the query. The LLM examines device names, groups, locations, and sensor types to understand which devices are relevant to the user’s question. In our example asking about “my greenhouse,” the system identifies that only devices belonging to the “greenhouse” group should be included in the analysis.
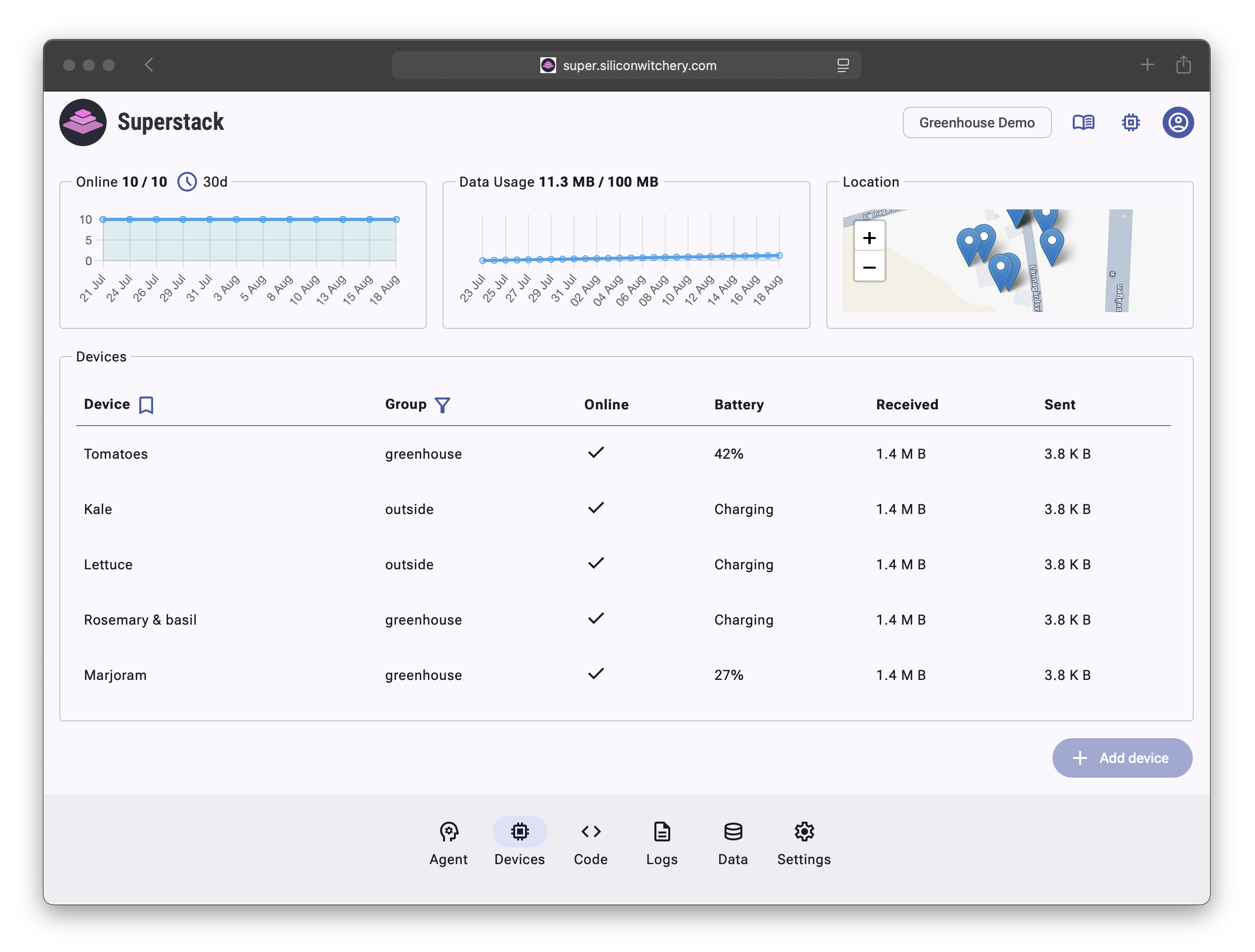
As shown above, the system would select devices like “Tomatoes,” “Rosemary & basil,” and “Marjoram” from the greenhouse group, while excluding “Kale” and “Lettuce” from the outside group. The system also inspects the JSON data structure from these devices to understand reporting frequency, available sensor fields, and data patterns.
Since no specific time range was provided in the query, the Filter tool assumes a reasonable default timeframe to ensure current and relevant data. It will look for the most recent temperature reading from each greenhouse device within the last few hours, ensuring that the analysis reflects the current state rather than stale data. If a device’s last reported temperature is too old (for example, more than 6-12 hours depending on the expected reporting frequency), that device will be excluded from the calculation to maintain data quality and relevance.
The output is a precise filter specification that will select only the relevant, recent temperature readings from active greenhouse devices—no raw data is shared with the AI provider.
2. Analyze
Using the data structure understanding from Step 1, this step generates a deterministic algorithm tailored to answer the specific query. The LLM creates executable code that will perform the exact calculation needed—in our temperature average example, it generates code to compute the mean of temperature values while properly handling missing data points, different units of measurement, and varying reporting frequencies across devices.
The algorithm might include statistical validation, outlier detection, or temporal aggregation depending on the complexity of the query. Importantly, the LLM only generates the analysis code—it never sees or processes your actual data. This generated algorithm then executes in Superstack’s secure runtime environment, processing only the filtered data to produce a precise numerical result.
3. Explain
The final step takes the computed results along with the detailed reasoning from both previous steps and synthesizes them into a clear, contextual answer. It draws upon the user’s domain context (such as device roles and deployment settings), chat history for conversational continuity, and the specific reasoning used in filtering and analysis to craft an appropriate response.
In our greenhouse temperature example, it would present the calculated average along with relevant context such as which devices contributed to the calculation, the time period analyzed, any data quality considerations encountered, and suggestions for follow-up questions. The response is formatted appropriately whether accessed through the web interface or API, maintaining both human readability and programmatic usability.
Key Benefits
This orchestrated approach delivers several critical advantages over traditional data analysis tools and naive LLM implementations:
Model agnostic: Each step can use the optimal model for its specific task—whether that’s GPT-5 for complex reasoning or a smaller, faster model for simple filtering. This flexibility allows us to quickly adopt new models and optimize for both performance and cost as the AI landscape evolves.
Data sovereignty: Your IoT data never leaves Superstack’s infrastructure. AI providers only see metadata, data structures, and generated algorithms—never your actual sensor readings or device information. This ensures compliance with data privacy regulations and eliminates concerns about sensitive operational data being used to train external models.
Deterministic accuracy: Unlike direct LLM analysis which can hallucinate or make calculation errors, our approach generates verifiable code that produces mathematically correct results. The separation between reasoning (LLM) and computation (deterministic algorithms) eliminates the reliability issues that plague other AI data analysis tools.
Contextual precision: The complete system context—including chat history, deployment-specific roles, and device metadata—is available at each step. This enables fine-tuned prompting that produces more accurate and relevant results than generic data analysis tools, while understanding domain-specific terminology and relationships.
Scalable complexity: The system handles everything from simple averages to sophisticated statistical analysis, automatically generating appropriate algorithms based on query complexity. As your data needs grow, the agent adapts without requiring manual reconfiguration.
The conversational interface is accessible both through our web application and programmatically via REST API, making it easy to integrate natural language data analysis into your own applications or workflows.
GPT5 vs GPT4.1
To evaluate the practical differences between GPT-4.1 and GPT-5 in our agent pipeline, we conducted a series of tests using solar panel data from a ranch deployment in Boulder, Colorado. The setup consists of two 20-square-meter solar arrays—one mounted on a house roof and another on a barn—with panels reporting power output every 15 minutes throughout the year. This high-frequency data creates a substantial dataset perfect for testing the models’ analytical capabilities.
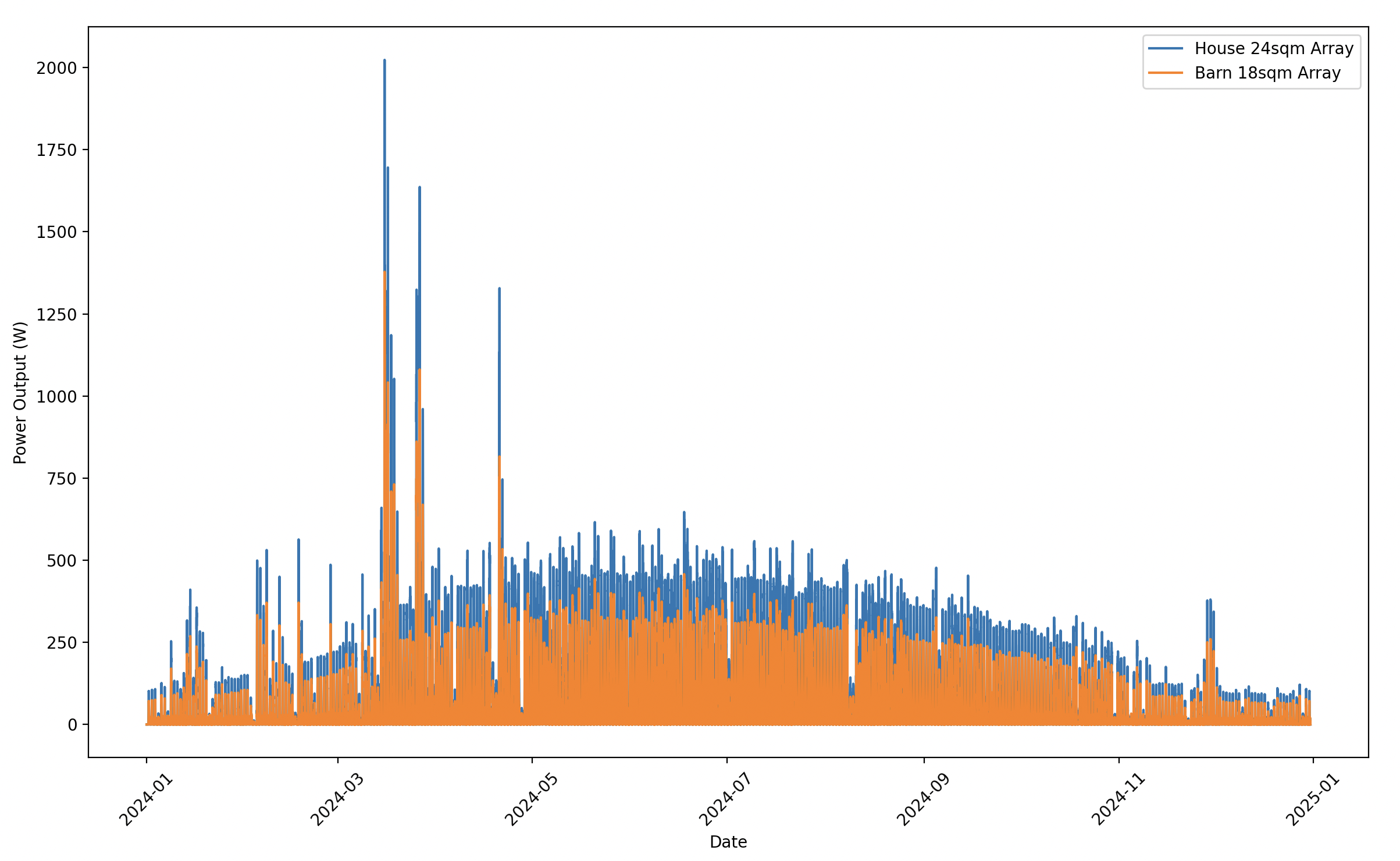
This solar deployment exemplifies why Superstack’s filtered approach is essential for real IoT analytics. With readings every 15 minutes from multiple panels across a full year, the dataset contains over 70,000 individual data points. Naively sending this raw data to an AI provider would cost hundreds of dollars per query due to token pricing, and would frequently exceed context limits entirely—GPT-4’s 128k token limit could only accommodate a fraction of the year’s data. More critically, LLMs perform poorly on large numerical datasets, often hallucinating patterns or dropping precision in calculations. Superstack’s architecture solves this by using the LLM only for reasoning about which data to analyze and how to analyze it, while keeping the actual number-crunching deterministic and local.
Test Setup
We designed three progressively complex queries to stress-test both models:
- “What was the average power output in May?” - A straightforward aggregation requiring temporal filtering and basic statistics
- “What day in May had the best power output?” - Requires grouping by date, calculating daily totals, and identifying the maximum
- “How many watt hours were generated in May?” - The most complex query, requiring unit conversion from instantaneous power readings to cumulative energy over time
Each query was tested multiple times across both model versions to assess consistency and reliability.
Results and Analysis
| Query | GPT4.1 result | GPT5 result |
|---|---|---|
| “What was the average power output in May?” | Filter passed: 10/10 Analysis passed: 10/10 | Filter passed: 10/10 Analysis passed: 10/10 |
| “What day in May had the best power output?” | Filter passed: 5/10 Analysis passed: 10/10 | Filter passed: 10/10 Analysis passed: 10/10 |
| “How many watt hours were generated in May?” | Filter passed: 10/10 Analysis passed: 4/10 | Filter passed: 10/10 Analysis passed: 10/10 |
The results reveal an interesting pattern: different query complexities cause failures at different stages of the pipeline, highlighting the distinct reasoning challenges each step presents.
Query 1: Average Power Output
Both models achieved perfect reliability across all pipeline steps. The filtering correctly identified May data from both solar arrays, and the analysis consistently generated appropriate aggregation code. This baseline query demonstrates that both GPT-4.1 and GPT-5 excel at straightforward temporal filtering and basic statistical operations.
Query 2: Best Day Identification
Here we see a fascinating inversion: GPT-4.1’s failures occurred entirely in the Filter step (5/10 success rate), while the Analysis step remained perfectly reliable (10/10). The model struggled to correctly interpret “best day” in the context of solar data, sometimes filtering for individual peak readings rather than daily aggregates, or misunderstanding the temporal scope. However, when the filtering succeeded, GPT-4.1 consistently generated correct daily grouping and maximum-finding algorithms.
GPT-5 resolved these Filter step issues completely, demonstrating superior semantic understanding of the query intent and temporal relationships.
Query 3: Energy Calculation (Watt Hours)
This query showed the opposite failure pattern: GPT-4.1’s Filter step worked perfectly (10/10), correctly identifying all relevant power readings from May. However, the Analysis step failed frequently (4/10 success rate), struggling with the mathematical complexity of converting instantaneous power readings to cumulative energy. Common failures included treating power readings as already-integrated energy values, incorrect time interval calculations, or generating algorithms that summed watts instead of watt-hours.
GPT-5’s superior mathematical reasoning eliminated these Analysis step failures entirely, consistently generating correct temporal integration logic: sum(power_reading * 0.25 hours) across all 15-minute intervals.
This pattern suggests that as query complexity increases, different aspects of language understanding become the limiting factor—semantic comprehension for Query 2, mathematical reasoning for Query 3.
Performance Implications
| Query | GPT4.1 avg time taken | GPT5 avg time taken |
|---|---|---|
| “What was the average power output in May?” | Filter: 11.5s Analysis: 13.4s | Filter: 31.1s Analysis: 69.7s |
| “What day in May had the best power output?” | Filter: 10.5s Analysis: 16.1s | Filter: 28.3s Analysis: 63.7s |
| “How many watt hours were generated in May?” | Filter: 10.5s Analysis: 22.1s | Filter: 33.7s Analysis: 78.9s |
The performance impact of GPT-5 is more substantial than initially expected. GPT-5 queries take 2.5-3x longer than GPT-4.1 across both pipeline steps, with the Analysis step showing particularly significant increases (4-5x slower). The Filter step, while containing less complex reasoning, still shows considerable latency increases (2.5-3x slower).
Interestingly, query complexity affects GPT-4.1 timing more dramatically than GPT-5. GPT-4.1’s Analysis step ranges from 13.4s to 22.1s depending on mathematical complexity, while GPT-5 shows more consistent timing regardless of query type.
Migration Plan
While GPT-5’s superior accuracy is compelling, the 3-5x latency increase makes immediate full deployment impractical for production use. Our rollout strategy balances the benefits of improved reasoning with user experience requirements.
We’re planning a phased GPT-5 rollout as OpenAI continues optimizing inference speeds over the coming months. Based on our experience with OpenAI’s model launches, we expect GPT-5 latency should decrease by 40-60% within the next quarter. Once GPT-5 achieves sub-30-second response times for complex queries, we’ll begin enabling that option for high-complexity analytical workloads.
Additionally, to allow for further flexibility, we plan to allow users to choose between fast and slow responses, enabling a tradeoff for different kinds of use cases.
These modes will be configurable both at the deployment level (for consistent team preferences) and per-query via API parameters (for application-specific requirements). This flexibility ensures that time-sensitive operational dashboards can maintain responsiveness while detailed analytical reports can leverage GPT-5’s superior reasoning capabilities.
Conclusion
The evolution from GPT-4.1 to GPT-5 represents a significant step forward in AI-powered data analysis, but not without important trade-offs. Our solar panel testing demonstrates that while GPT-5 delivers measurably better accuracy—particularly for complex mathematical operations and nuanced query interpretation—the substantial latency increase requires careful consideration of when and how to deploy it.
The key insight from our analysis is that different types of complexity challenge different parts of the AI pipeline. Semantic understanding failures occur in the Filter step, while mathematical reasoning failures happen during Analysis. This granular understanding allows us to make smarter decisions about model selection and optimization strategies.
As the AI landscape continues to evolve rapidly, Superstack’s architecture provides the flexibility to adopt new models while maintaining the core principle that drives our approach: leverage AI for reasoning and planning, but keep your data processing deterministic and local. Whether you’re analyzing solar panel output, monitoring industrial sensors, or tracking environmental conditions, this architecture ensures that your IoT data analysis remains both powerful and reliable.
Ready to try natural language analytics on your IoT data? Get started with Superstack and experience the difference between naive LLM approaches and purpose-built IoT intelligence.
Learn More
Need Assistance?
For support or questions, email our engineering team for a free consultation.